728x90
0. Data
train : 80%
test : 20%
1. K-NN
neighbor == 3
import pandas as pd
from konlpy.tag import Kkma
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
csv_file_path = '../../data/spv/spv_data.csv'
try:
df = pd.read_csv(csv_file_path, encoding='utf-8')
except UnicodeDecodeError:
print('utf-8으로 디코딩하는 중 오류 발생. 다른 인코딩 시도 필요.')
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
kkma_kor = Kkma()
def KkmaLemNormalize_kor(text):
if '.' in text:
text = text.rsplit('.', 1)[0] # 확장자 제거 후 군집화
tokens = kkma_kor.morphs(text)
return ','.join(tokens)
tfidf_vect_kor = TfidfVectorizer(tokenizer=KkmaLemNormalize_kor, ngram_range=(1,2))
ftr_vector_kor = tfidf_vect_kor.fit_transform(df['CONTENT_TITLE'])
# 레이블 확인
target_column = 'CATEGORY' # 실제 레이블 컬럼 이름에 따라 수정해야 함
if target_column not in df.columns:
print(f"'{target_column}' 컬럼이 데이터프레임에 없습니다.")
else:
y = df[target_column]
X_train, X_test, y_train, y_test = train_test_split(ftr_vector_kor, y, test_size=0.2, random_state=42)
# RandomForestClassifier 또는 다른 분류 모델을 선택
model = KNeighborsClassifier(n_neighbors=3)
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# df['pred_category'] = y_pred
#
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
cm = confusion_matrix(y_test, y_pred)
print(cm)
import seaborn as sns
import matplotlib.pyplot as plt
# 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Class 0', 'Class 1', 'Class 2'], yticklabels=['Class 0', 'Class 1', 'Class 2'])
plt.title('KNN_Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
Accuracy: 0.9503
Confusion Matrix:

2. NB
import pandas as pd
from konlpy.tag import Kkma
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, confusion_matrix
csv_file_path = '../../data/spv/spv_data.csv'
try:
df = pd.read_csv(csv_file_path, encoding='utf-8')
except UnicodeDecodeError:
print('utf-8으로 디코딩하는 중 오류 발생. 다른 인코딩 시도 필요.')
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
kkma_kor = Kkma()
def KkmaLemNormalize_kor(text):
if '.' in text:
text = text.rsplit('.', 1)[0] # 확장자 제거 후 군집화
tokens = kkma_kor.morphs(text)
return ','.join(tokens)
tfidf_vect_kor = TfidfVectorizer(tokenizer=KkmaLemNormalize_kor, ngram_range=(1,2))
ftr_vector_kor = tfidf_vect_kor.fit_transform(df['CONTENT_TITLE'])
# 레이블 확인
target_column = 'CATEGORY' # 실제 레이블 컬럼 이름에 따라 수정해야 함
if target_column not in df.columns:
print(f"'{target_column}' 컬럼이 데이터프레임에 없습니다.")
else:
y = df[target_column]
X_train, X_test, y_train, y_test = train_test_split(ftr_vector_kor, y, test_size=0.2, random_state=42)
# RandomForestClassifier 또는 다른 분류 모델을 선택
model = MultinomialNB()
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# df['pred_category'] = y_pred
#
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
cm = confusion_matrix(y_test, y_pred)
print(cm)
import seaborn as sns
import matplotlib.pyplot as plt
# 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Class 0', 'Class 1', 'Class 2'], yticklabels=['Class 0', 'Class 1', 'Class 2'])
plt.title('NB_Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
Accuracy: 0.9063
Confusion Matrix:
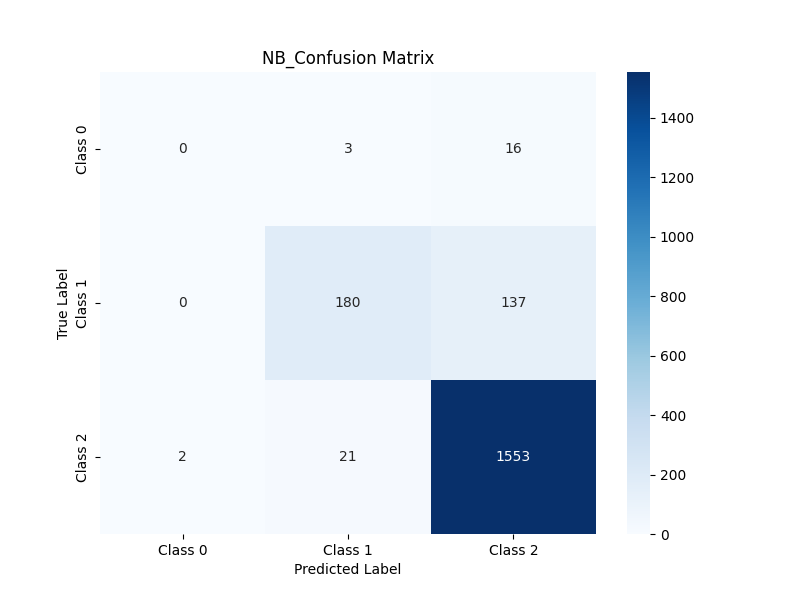
3. RF
import pandas as pd
from konlpy.tag import Kkma
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
csv_file_path = '../../data/spv/spv_data.csv'
try:
df = pd.read_csv(csv_file_path, encoding='utf-8')
except UnicodeDecodeError:
print('utf-8으로 디코딩하는 중 오류 발생. 다른 인코딩 시도 필요.')
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
kkma_kor = Kkma()
def KkmaLemNormalize_kor(text):
if '.' in text:
text = text.rsplit('.', 1)[0] # 확장자 제거 후 군집화
tokens = kkma_kor.morphs(text)
return ','.join(tokens)
tfidf_vect_kor = TfidfVectorizer(tokenizer=KkmaLemNormalize_kor, ngram_range=(1,2))
ftr_vector_kor = tfidf_vect_kor.fit_transform(df['CONTENT_TITLE'])
# 레이블 확인
target_column = 'CATEGORY' # 실제 레이블 컬럼 이름에 따라 수정해야 함
if target_column not in df.columns:
print(f"'{target_column}' 컬럼이 데이터프레임에 없습니다.")
else:
y = df[target_column]
X_train, X_test, y_train, y_test = train_test_split(ftr_vector_kor, y, test_size=0.2, random_state=42)
# RandomForestClassifier 또는 다른 분류 모델을 선택
model = RandomForestClassifier()
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# df['pred_category'] = y_pred
#
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
cm = confusion_matrix(y_test, y_pred)
print(cm)
import seaborn as sns
import matplotlib.pyplot as plt
# 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Class 0', 'Class 1', 'Class 2'], yticklabels=['Class 0', 'Class 1', 'Class 2'])
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()Accuracy: 0.9848
Confusion Matrix:
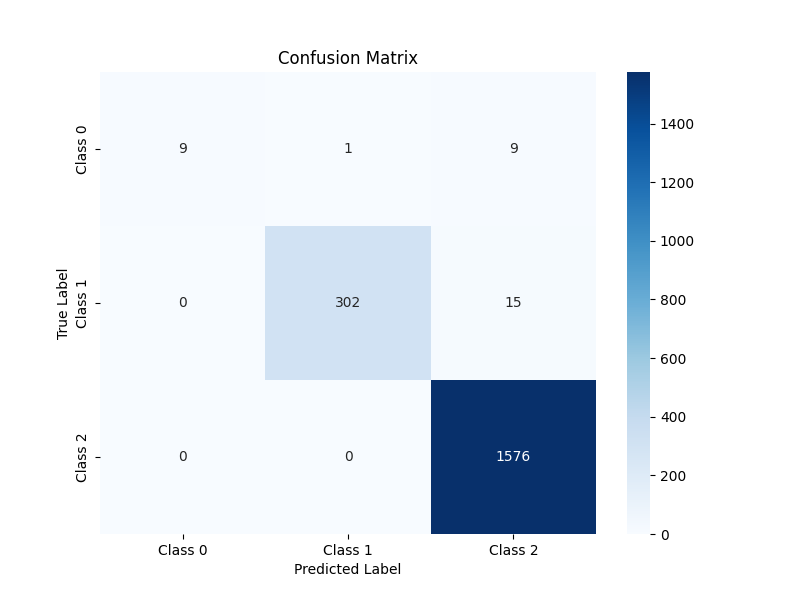
4. SVM
import pandas as pd
from konlpy.tag import Kkma
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix
csv_file_path = '../../data/spv/spv_data.csv'
try:
df = pd.read_csv(csv_file_path, encoding='utf-8')
except UnicodeDecodeError:
print('utf-8으로 디코딩하는 중 오류 발생. 다른 인코딩 시도 필요.')
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
kkma_kor = Kkma()
def KkmaLemNormalize_kor(text):
if '.' in text:
text = text.rsplit('.', 1)[0] # 확장자 제거 후 군집화
tokens = kkma_kor.morphs(text)
return ','.join(tokens)
tfidf_vect_kor = TfidfVectorizer(tokenizer=KkmaLemNormalize_kor, ngram_range=(1,2))
ftr_vector_kor = tfidf_vect_kor.fit_transform(df['CONTENT_TITLE'])
# 레이블 확인
target_column = 'CATEGORY' # 실제 레이블 컬럼 이름에 따라 수정해야 함
if target_column not in df.columns:
print(f"'{target_column}' 컬럼이 데이터프레임에 없습니다.")
else:
y = df[target_column]
X_train, X_test, y_train, y_test = train_test_split(ftr_vector_kor, y, test_size=0.2, random_state=42)
# RandomForestClassifier 또는 다른 분류 모델을 선택
model = SVC(kernel='linear')
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# df['pred_category'] = y_pred
#
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
cm = confusion_matrix(y_test, y_pred)
print(cm)
import seaborn as sns
import matplotlib.pyplot as plt
# 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Class 0', 'Class 1', 'Class 2'], yticklabels=['Class 0', 'Class 1', 'Class 2'])
plt.title('SVM_Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
Accuracy: 0.9900
Confusion Matrix:
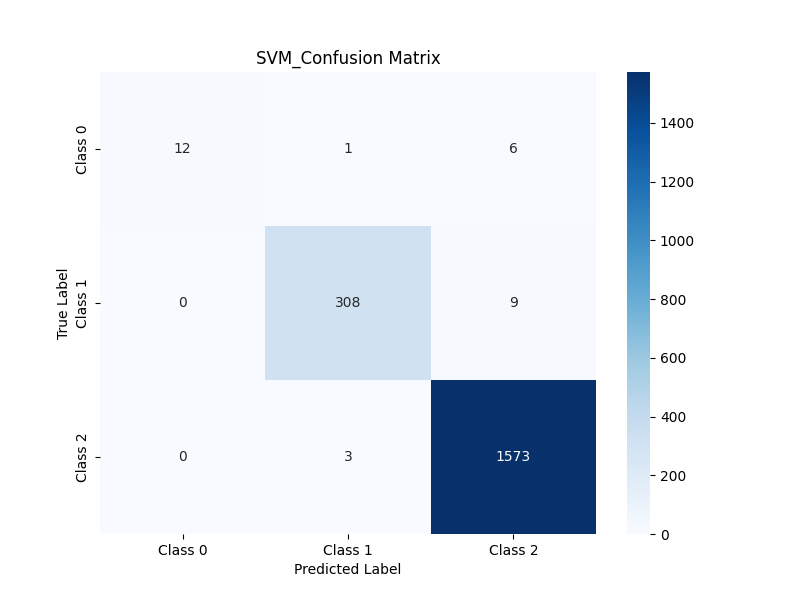
5. 결과 비교
Total data : 9560
Train data : 7648개
X_train : (7648, 4313)
Y_train : (7648,)
Test data : 1912 개
X_test : (1912, 4313)
Y_test:(1912,)
| 정확도 | confusion matrix | |
| KNN | 0.9503 | [[ 11 1 7] [ 0 282 35] [ 2 50 1524]] |
| NB | 0.9063 | [[ 0 3 16] [ 0 180 137] [ 2 21 1553]] |
| RF | 0.9848 | [[ 9 1 9] [ 0 302 15] [ 0 0 1576]] |
| SVM | 0.9900 | [[ 12 1 6] [ 0 308 9] [ 0 3 1573]] |
정확도가 99인게 오버피팅 관련해서 마음에 걸리긴 하지만, 데이터가 얼마 없는 것도 감수해야 하기에
그래도 정확도가 높은 모델인 SVM으로 최종 테스트를 진행하기로 결정

728x90
'😒 저 저 저 개념없는 나 > ⛓️ DL & ML' 카테고리의 다른 글
| [문서 제목 자동 분류 작업 | Classification] 3. 최종 실행 | 인턴 (0) | 2024.01.29 |
|---|---|
| [문서 제목 자동 분류 작업 | Classification] 1. 데이터 생성 및 최적 모델 탐지 | 인턴 (2) | 2024.01.29 |
| [문서 제목 자동 분류 작업 | Clustering] 5. 한국어 Text Clustering Word2Vec K-means | 인턴 (0) | 2024.01.17 |
| [문서 제목 자동 분류 작업 | Clustering] 4. 한국어 Text Clustering TF-IDF K-means | 인턴 (1) | 2024.01.15 |
| [문서 제목 자동 분류 작업 | Clustering] 3. K-Means 알고리즘 학습 적용 군집화 | 인턴 (0) | 2024.01.15 |